Research entry
Physics-Inspired k-Means Quantization for LLM Weights
Completed · March 2026
26 experiments compressing GPT-2 with physics-motivated k-means codebook quantization. Best result: PPL=84.2 at 0.836 bits per weight — 38× compression vs FP32. Null results triangulate the GPTQ design from first principles.
Motivation
The connection between statistical physics and LLM quantization is not just metaphorical.
In the Ising model, each spin takes a value from a discrete alphabet {−1, +1}. In LLM quantization, each weight block is replaced by a centroid from a discrete codebook. The optimal codebook placement — minimising the loss under perturbation — is equivalent to finding the ground state of a spin-glass Hamiltonian where the coupling matrix is the loss Hessian H_W. Strong couplings (large H_ij) correspond to sensitive weight directions; weak couplings to directions the model barely notices.
This framing suggested a concrete research question: can physics intuitions — Hessian sensitivity, renormalisation group layer ordering, SmoothQuant-style scale migration — improve on flat k-means quantization at the same bit budget?
The answer turned out to be: sometimes yes, often no, and the failures are as informative as the successes.
Method
Core technique: per-row k-means with activation calibration
Each weight matrix row is quantized independently using k-means:
block_dim=8— each row is split into non-overlapping blocks of 8 weightsKcentroids per row — each block is replaced by its nearest centroid indexbpw = log₂(K) / block_dim— bits per weight- Activation calibration — blocks are weighted by mean input activation magnitude
||x_j||²during k-means, aligning the codebook with the actual inference distribution
Non-uniform K allocation
Layer sensitivity was measured by single-layer isolation (Exp 18): swap one layer at a time, record ΔPPL. The top-N most sensitive MLP layers receive K=128; the rest K=64. This gives a smooth PPL/bpw Pareto frontier controlled by a single integer N.
Attention layers
Attention sublayers have exactly 96 blocks per row (768 ÷ 8). Setting K=96 gives every block its own centroid — exact reconstruction regardless of calibration. Attention quantization is therefore lossless at zero cost across all MLP configurations.
Results
Pareto frontier
Full model quantization of GPT-2 (117M parameters), all 48 sublayers (MLP + attention):

| N (top-K=128 layers) | bpw | PPL | vs FP32 |
|---|---|---|---|
| 0 (all K=64) | 0.787 | 321.7 | 5.08× |
| 4 | 0.796 | 217.0 | 3.43× |
| 8 | 0.805 | 180.0 | 2.85× |
| 12 | 0.813 | 146.6 | 2.32× |
| 16 | 0.822 | 120.1 | 1.90× |
| 24 (all K=128) | 0.836 | 84.2 | 1.33× |
FP32 baseline: PPL=63.3. Best result: PPL=84.2 at 0.836 bpw — 38× parameter compression vs FP32 bit count.
Calibration improves every N by 10–27% at no additional bpw cost. The two techniques compose cleanly: non-uniform K controls which layers get the bigger codebook; calibration shifts centroid placement toward the actual weight-activation distribution within each layer.
Layer-dependent phase transition
Quantization error does not propagate uniformly across layers. In the renormalisation group (RG) picture, the first transformer block operates at the “UV scale” — it processes raw token embeddings, and errors there are amplified by every downstream nonlinearity. Later blocks operate at the “IR scale” where perturbations are absorbed by the residual stream.
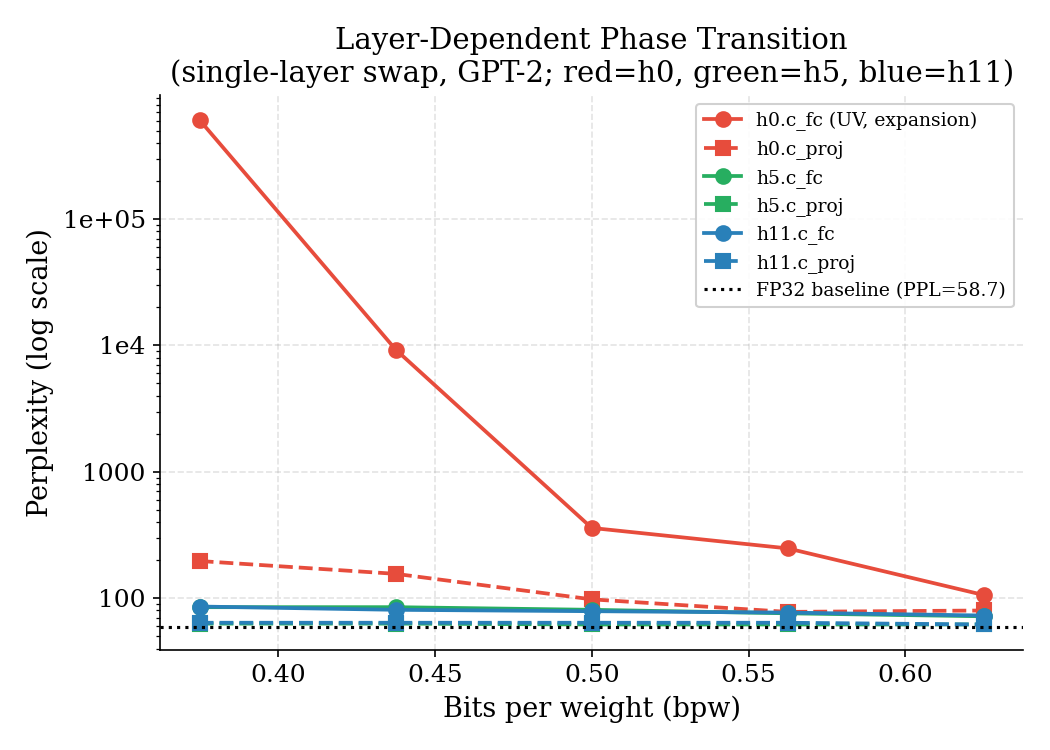
The effect is dramatic: at bpw=0.375, h0.c_fc reaches PPL=606,633 — complete model
collapse — while h5.c_proj at the same bpw gives PPL=63, indistinguishable from FP32.
The critical bpw for h0.c_fc is 0.5; every other tested layer is stable at 0.375 or below.
The c_fc (expansion, 768→3072) vs c_proj (compression, 3072→768) asymmetry also
holds across all layers: expansion layers feed directly into the GELU nonlinearity, where
quantization errors near zero get binary-amplified. Projection layers output into the
residual stream, which absorbs small errors through the identity shortcut.
Why the greedy budget allocation fails
Given layer sensitivity scores from single-layer isolation (Exp 18), a greedy algorithm was tested: at each step, upgrade whichever layer has the highest sensitivity-per-bpw gain. The result was consistently worse than the simple binary Top-N scheme.
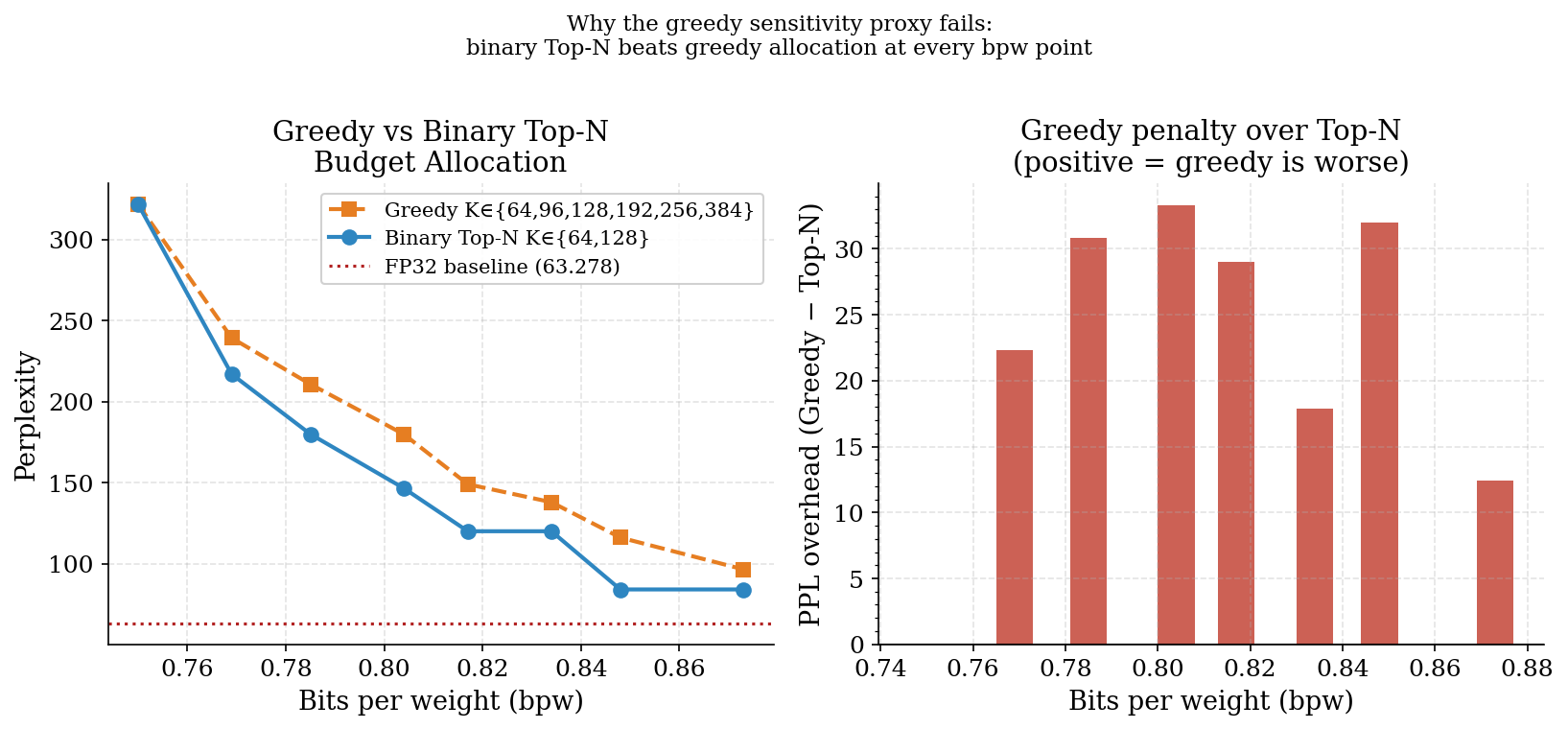
The greedy algorithm concentrates bits on a small number of high-sensitivity layers,
pushing h6.c_proj to K=384 before upgrading most other layers past K=64. The
sensitivity scores from Exp 18 are valid for ranking which layers should be upgraded
first, but they are not valid as marginal benefit proxies for subsequent upgrades.
The dominant gain comes from the first step (K=64→K=128); further upgrades have sharply
diminishing returns that the proxy overestimates. The binary Top-N scheme encodes the
correct inductive bias: upgrade each layer exactly once.
The SmoothQuant breakthrough — and its failure landscape
A SmoothQuant-style scale migration (Xiao et al., 2022) was tested on a single layer: absorb a per-column scale into the activation path rather than the weight reconstruction, then run flat k-means on the smooth weights. At α=0.5 (geometric mean of weight-std and activation-magnitude scaling), this recovered 65% of the quantization gap at identical bpw.
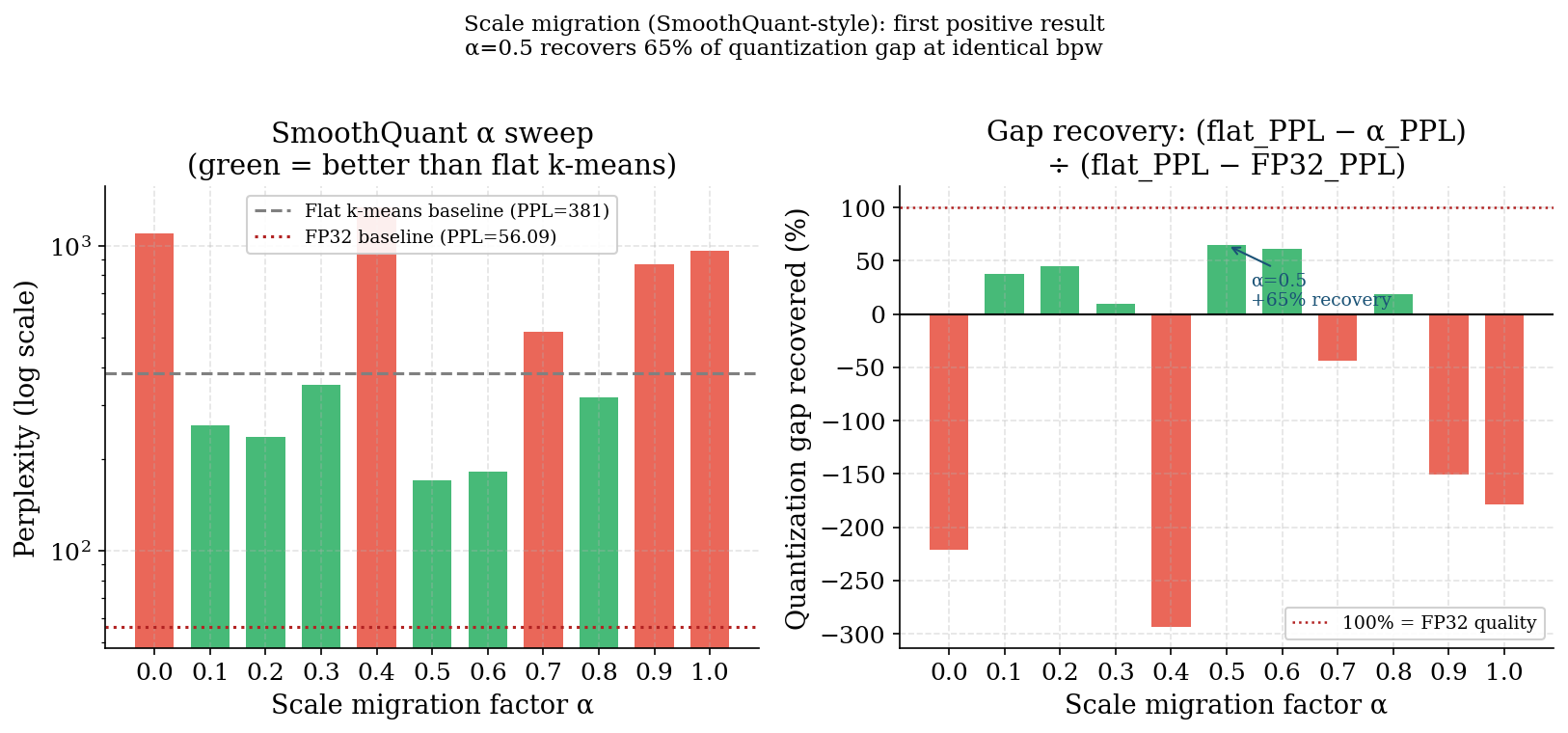
The landscape around the optimum is not smooth. α=0.4 produces PPL=1,334 (worse than flat k-means at 381) immediately adjacent to the optimum at α=0.5 (PPL=170). This chaotic behaviour is consistent with the rough energy landscapes seen in the phase transition experiments: at certain scale configurations, k-means initialisation lands in a bad basin and never escapes.
This result was not carried forward into the full multi-layer pipeline — single-layer SmoothQuant requires coordinated scale absorption across adjacent layers (the activation scaling must be absorbed by the preceding LayerNorm), which adds implementation complexity. It remains the clearest positive result from the Hessian-motivated experiments.
What Didn’t Work
The null results are as informative as the positives. Three natural physics-inspired approaches were systematically eliminated:
DCT / Fourier quantization (Exp 1) — GPT-2 weight blocks show a completely flat DCT energy spectrum (~6.25% per mode, identical to white noise). There is no low-frequency spatial structure to exploit. JPEG-style compression of raw weight blocks is not viable. This is consistent with the QuIP# finding that random Hadamard incoherence processing is required before scalar quantization can work in Fourier space.
SVD truncation (Exp 2) — All 24 MLP layers show spectral decay exponent α≈0.5, consistent with the Marchenko-Pastur distribution of large random matrices. The weights require ~65% of modes to capture 90% variance — they are not low-rank in any useful sense. SVD needs 3.3× more bits than flat k-means to achieve the same RMSE at bpw≈0.5. SVD truncation works for fine-tuning deltas ΔW (which are genuinely low-rank) but not for compressing base weights (which sit in the Marchenko-Pastur bulk as a consequence of SGD noise during training).
Diagonal H-weighted block k-means (Exps 3–6) — Weighting k-means by diagonal Hessian entries (H_diag[j] = E[x_j²]) consistently improved the H-weighted RMSE metric by 4–9%, but catastrophically degraded perplexity. The root cause: H-RMSE is an average over calibration activations, weighted by E[x_j²]. Cold input dimensions (low H_diag) have small weights in the metric — but they are not zero at inference. Any scheme that concentrates codebook capacity on hot dimensions leaves cold dimensions poorly represented, producing large reconstruction errors that dominate PPL through rare but non-zero token activations. Flat k-means avoids this by treating all weights uniformly; its PPL=381 cannot be beaten by any diagonal H-weighted variant regardless of block layout, normalization, or clipping.
Together these three null results triangulate the GPTQ design from first principles: you cannot exploit Fourier structure (it doesn’t exist), you cannot truncate globally (the weights are full-rank), and you cannot use a diagonal Hessian approximation with shared codebooks (H-RMSE ≠ PPL in the tail). The correct approach requires the full covariance rotation — quantizing in the eigenbasis of E[xx^T] — which is exactly what GPTQ’s Cholesky-based solver approximates.
Conclusion
26 experiments across 9 weeks produced a clear picture of what works and what doesn’t for per-row k-means quantization of GPT-2:
- Activation calibration is free and consistently useful above K=64
- Non-uniform K allocation (binary Top-N by sensitivity rank) is the right way to use layer sensitivity scores — greedy multi-step allocation is worse at every bpw
- Attention layers quantize losslessly at K=n_blocks_per_row; they cost nothing
- SmoothQuant-style scale migration recovers 65% of the gap on a single layer but requires careful coordination across layers to deploy at scale
- Diagonal H-weighted codebooks cannot improve PPL over flat k-means regardless of implementation — the path to Hessian-aware improvement requires full covariance rotation
The final full-model frontier reaches PPL=84.2 at 0.836 bpw — 1.33× the FP32 baseline at approximately 38× compression. Future directions include residual (multi-stage) quantization, scaling to GPT-2 medium/large to test universality of the Marchenko-Pastur finding, and implementing full GPTQ-style error propagation on top of the activation- calibrated codebook.